Document technique à l’exploitation de Azure Cognitive Search par l’application Courrier du CAM.
Vue d’ensemble
Azure Cognitive Search est un service permettant d’isoler l’indexation et le traitement d’une grande masse de données. En l’occurrence nous y avons recours pour la recherche de courrier qui actuellement dépasse les 400 000. Cette fonctionnalité de recherche ‘avancée’ est représentée par la structure suivante :
![]() : L’application courrier interroge l’index du service de recherche.
: L’application courrier interroge l’index du service de recherche.
![]() : Le service de recherche est l’intermédiaire entre l’application et la base de données. Il effectue la recherche et rapatrie les données pour l’application.
: Le service de recherche est l’intermédiaire entre l’application et la base de données. Il effectue la recherche et rapatrie les données pour l’application.
![]() : La base de données de l’application courrier.
: La base de données de l’application courrier.
Search Service
Le service de recherche est entièrement configurable sur le portail Azure. Ce service nécessite 3 différentes configurations :
- Celle de l’index
- Celle de l’indexer
- Celle de la source de donnée Dans l’ordre, il faudra en premier créer la source, puis l’index et enfin lier l’index et la source par l’indexer.
L’index
Création d’un index
Depuis le portail Azure et le service de recherche. Il est possible de créer un nouvel index.

Cet index représente les données que nous souhaiterons manipulées.
Les champs
Il faudra y renseigner toutes les données que nous souhaitons rapatrier. Ainsi que celles sur lesquelles nous souhaiterons appliquer de la recherche, du filtrage ou du tri. Limiter ces choix au strict minimum est nécessaire pour optimiser les performances de l’index.
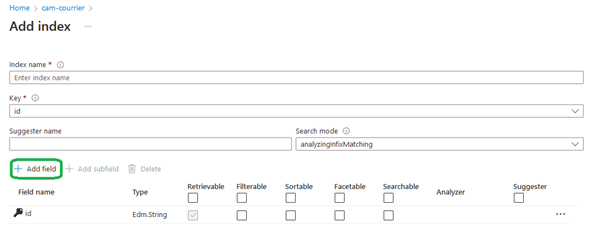
Attention, les champs ajoutés à l’index ne peuvent être ni modifiés, ni supprimés. Bien vérifier que leurs types sont correctes ainsi que le choix de leurs affectations avant de cliquer sur enregistrer. Si une erreur sur un des champs est constatée il faudra supprimer la totalité de l’index et le recréer.
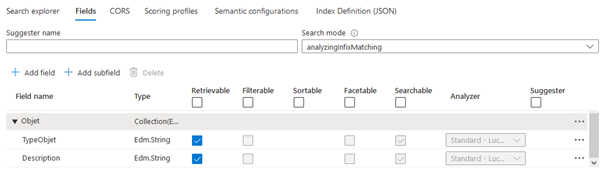
Les champs complexes
L’ajout d’un champ de type complexe nécessite que la table source soit une vue. (Voir chapitre sur la source de données). Pour ces champs il sera nécessaire de renseigner les sous champs sur lesquels nous souhaitons agir. Attention, on ne peut pas trier sur des sous-champs.
L’indexer
L’indexer est le moteur du service. Il permettra à l’aide de l’index et la source de créer son algorithme de recherche le plus performant.
Création de l’indexer
Depuis le service de recherche dans le portail Azure, il est possible de créer un nouvel indexer. Il est nécessaire de créer un indexer par index.
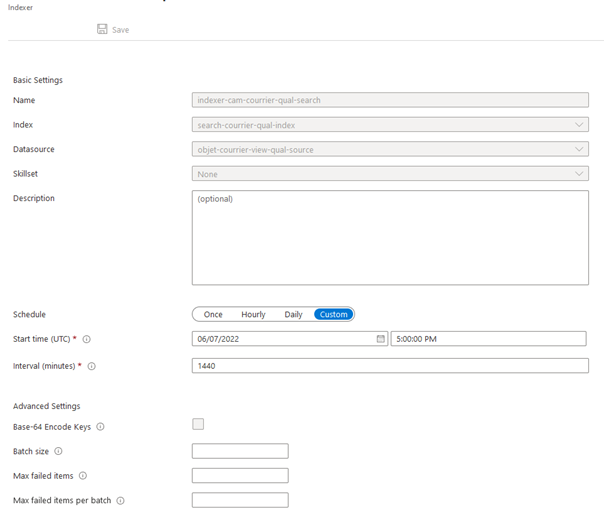
Il est nécessaire de renseigner à minima l’index et la source préalablement créés. Il est également possible de décider la fréquence de déclenchement de l’indexation.
La fréquence d’indexation
Déclencher de nouvelles indexations automatisées permet de rajouter à la recherche, lors de l’utilisation de l’index, les nouvelles lignes de la table créé depuis l’ancien déclenchement de l’indexation. Les données ajoutées entre deux indexations ne peuvent donc pas être rapatriées en utilisant Azure Cognitive Search.
La source de donnée
La source de donnée représente la table sur laquelle l’indexer va indexer les données.
Création de la source de donnée
Il faut tout simplement renseigner la base de données et la table lors de la création d’une nouvelle source de données.
Les données complexes
Si l’indexation doit de faire sur des données qui sont présentes dans d’autre tables, accessible à l’aide d’une clef étrangère, il sera nécessaire de créer une vue comportant la totalité des données de cet ‘enfant’ en lieu et place de la clef étrangère. Pour plus d’information suivre ce document : https://docs.microsoft.com/en-us/azure/search/search-howto-complex-data-types?tabs=portal
La source devra donc être cette nouvelle vue au lieu de la table.
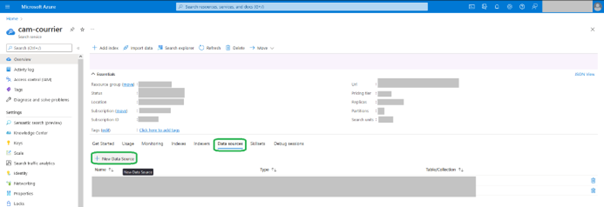
Suivie des modifications
Lors de la création de la source de données il sera possible de sélectionner « Track changes ». Il est nécessaire de cocher cette case si l’on souhaite pouvoir ensuite déclencher la mise a jour de l’indexation des données de manière automatisée.
Il est conseillé d’utiliser « Integrated change tracking » et d’autoriser le tracking sur la base et la table souhaité. Mais si l’on utilise des données complexes, et donc une vue, il ne sera pas possible d’utiliser cette option. Il faudra donc utiliser « High watermark column ».
Mise à jour de l’index
Deux types de modifications de l’index sont à noter :
- L’ajout d’un champ
- La modification d’un champ. Ces deux étapes nécessiteront ensuite de relancer l’indexer
Ajout d’un champ
Depuis l’index en question il est possible d’ajouter un champ.
Modification d’un champ
Si l’on souhaite modifier les propriétés d’un champ déjà existant dans l’index, nous serons dans l’obligation de supprimer l’index dans sa totalité et de le reconstruire. Une procédure peut faciliter cette démarche.
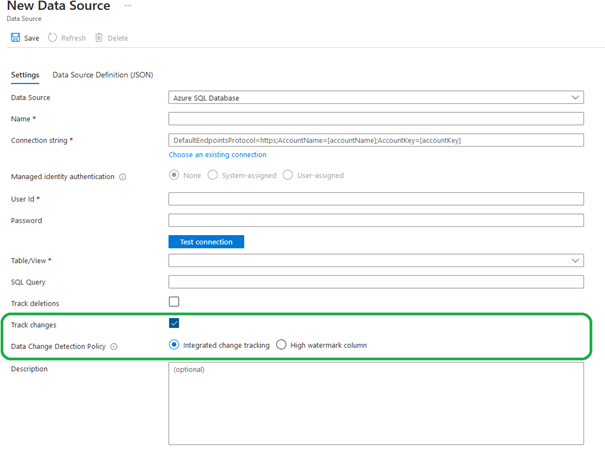
Exportation de l’index actuel
Pour l’index en question, sélectionner « Edit JSON ».
Copier l’ensemble du contenu du JSON dans un fichier text.
Supprimer l’index
Revenir à la liste des index, et supprimer l’index à modifier.

Création d’un index par importation
Cliquer ensuite sur « Add index » et choisir « JSON »
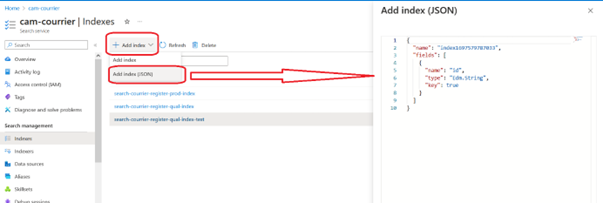
Dans le volet de droite, coller tout le contenu « fields » copié précédemment. Certaines lignes avec des valeurs « null » peuvent remonter en erreur, en rouge, vous pouvez les supprimer.

3.3 Relancer l’indexer
L’indexeur peut être relancé par un « reset » puis un « run » de l’indexer. Si le nombre de documents à indexer est trop élevé (> à 5minutes d’indexation) celui-ci échouera. Il faudra donc supprimer et recréer l’indexer.
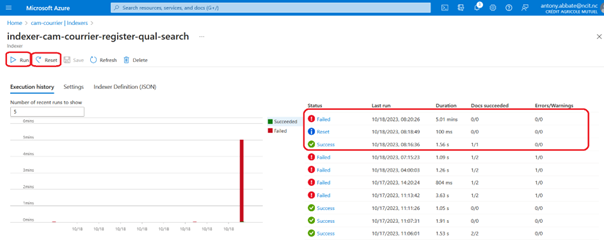
En cas d’échec du « run » à la suite du « reset » il faut supprimer l’indexer.
Lors de la suppression de l’indexer attention de ne supprimer que l’indexer et pas la source, ni l’index associés.
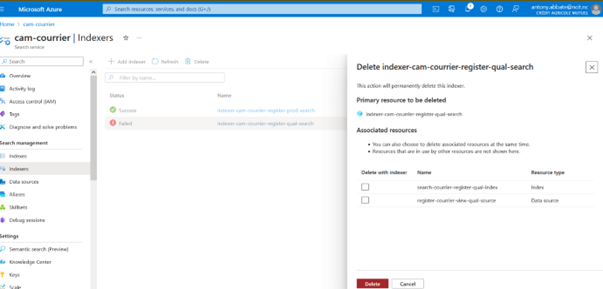
Il faut ensuite recréer l’indexer
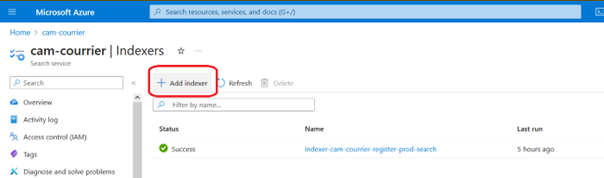
Renseigner les champs suivants avec vos données (source, index et fréquence d’indexation). Puis sauvegarder « Save ».
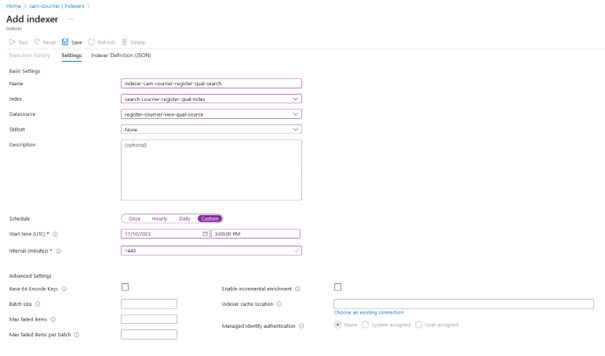
La création de l’indexer lancera une première indexation. Cette première indexation est autorisée à dépasser la limite de 5 minutes.
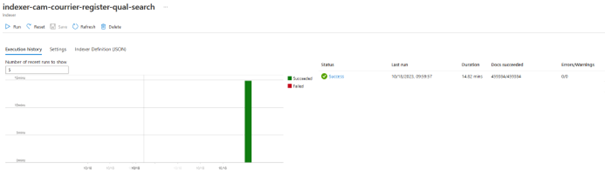
Veuillez laisser l’indexer démarrer le premier « run » tout seul, cela peut être déclenché dans la demi-heure suivant la création de l’indexer. S’il n’est pas déclencher au bout de, au moins, 15minutes, lancer le déclenchement manuellement par le bouton « run ».
Configuration de l’application
Les packages
Dans les NuGets packages il est nécessaire de disposer des packages :
- Microsoft.Azure.Search.Data : pour requêter les index souhaités.
- Azure.Search.Documents : Pour formater les données rapatriées du service de recherche.
Les connexions strings
Pour pouvoir communiquer avec le service il est nécessaire de renseigner trois connexions strings :
- SearchServiceUri : qui représente l’url du service
 ,
, - SearchServiceQueryApiKey : qui représente un des mots de passe d’accès au service
 ,
, - SearchServiceIndex : qui est le nom de l’index ciblé pour la recherche
 .
.
Utilisation de l’index
Pour effectuer une recherche il faut requêter directement l’index. Pour cela il faudra créer un client (new SearchIndexClient : en lui fournissant SearchServiceUri et SearchServiceQueryApiKey), et lui fournir l’index cible (GetSearchClient : en lui fournissant SearchServiceIndex).
On pourra ensuite requêter cet index (Task<Response<SearchResults<T>>> SearchAsync<T>(…)) en lui fournissant les instructions de recherche, de filtre et de tri. Il est également possible de limiter les données à rapatrier en ajoutant un select. Il n’est cependant pas possible de rapatrier plus de données que celles définies comme rapatriables par l’index. Plus d’informations sur les liens :